ICML 2019
摘要
In open-ended environments, autonomous learning agents must set their own goals and build their own curriculum through an intrinsically motivated exploration. They may consider a large diversity of goals, aiming to discover what is controllable in their environments, and what is not. Because some goals might prove easy and some impossible, agents must actively select which goal to practice at any moment, to maximize their overall mastery on the set of learnable goals. This paper proposes CURIOUS, an algorithm that leverages 1) a modular Universal Value Function Approximator with hindsight learning to achieve a diversity of goals of different kinds within a unique policy and 2) an automated curriculum learning mechanism that biases the attention of the agent towards goals maximizing the absolute learning progress. Agents focus sequentially on goals of increasing complexity, and focus back on goals that are being forgotten. Experiments conducted in a new modular-goal robotic environment show the resulting developmental self-organization of a learning curriculum, and demonstrate properties of robustness to distracting goals, forgetting and changes in body properties.
在开放式环境中,自主学习的智能体必须通过内在动机的探索来设定自己的目标和建立自己的课程。他们可能会考虑大量不同的目标,旨在发现环境中哪些是可控的,哪些是不可控的。因为有些目标可能被证明是容易的,而有些则是不可能的,所以智能体必须在任何时候主动选择哪个目标,以最大限度地提高他们对可学习目标集的总体掌握程度。本文提出的CURIOUS是一种算法,它利用1)模块化的通用价值函数方法和事后学习,在一个独特的策略中实现不同种类的目标;2)自动课程学习机制,使智能体的注意力偏向于绝对学习进度最大化的目标。智能体依次关注日益复杂的目标,并重新关注被遗忘的目标。在一个新的模块化目标机器人环境中进行的实验显示了由此产生的学习课程的发展性自组织,并展示了对分散的目标、遗忘和身体属性的变化的稳健性特性。
研究动机
- 自动进行目标设定,自组织的课程学习
- 基于Modular goal的新表达,即将不同种类目标归纳为模块modular
主要贡献
- 引入modular模块目标编码,可以学习不同种类的目标(即不同module对应的目标集)
- 跨modular的目标重放,即不同modular、goal都可进行经验重放
- 从IMGEP的角度来看,实现了一个单模块多目标策略,一种新的解决方案区别于基于种群的方法
方法描述
A Modular Multi-Goal Architecture using Universal Approximators
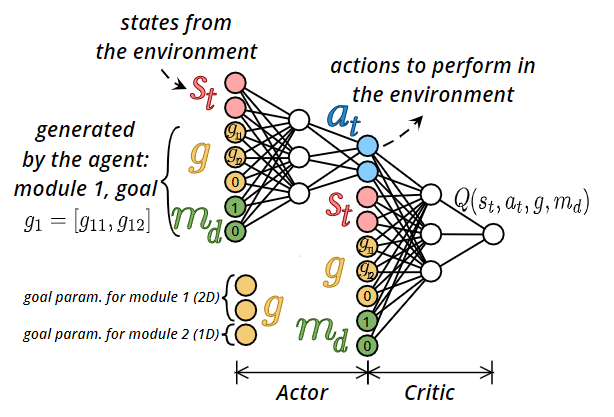
新的编码方式:Module:one-hot向量编码;Goal:目标状态编码
- 目标状态编码不同module不共享,相互独立(非当前module的维度置0)
- m和g均可用在经验回放时进行替换
Module and Goal Selection, Cross-Module Learning, Cross-Goal Learning
环境交互:
Module选择:学习进度评估Learning Progress Estimation
- 用于评估当前Module的学习进度(完成度、遗忘度)
- 完成$M_i$的能力(即最近$l$个轨迹的成功率):$C_{M_{i}}\left(n_{e v a l}^{(i)}\right)=\frac{1}{l} \sum_{j=0}^{l-1} \text { results }(i)\left(n_{e v a l}^{(i)}-j\right)$
- LP值(相邻两次能力评测的差值):$L P_{M_{i}}\left(n_{e v a l}^{(i)}\right)=C_{M_{i}}\left(n_{e v a l}^{(i)}\right)-C_{M_{i}}\left(n_{e v a l}^{(i)}-l\right)$
LP优先级(引入epsilon-greedy):$p_{L P}\left(M_{i}\right)=\epsilon \times \frac{1}{N}+(1-\epsilon) \times \frac{\left|L P_{M_{i}}\right|}{\sum_{j=1}^{N}\left|L P_{M_{j}}\right|}$
- LP值为正表示强化,LP值为负表示遗忘
- Goal选择:从目标集合中平均采样
采样训练
- Cross-Module:根据LP分布从Module集合中采样,替换当前轨迹的Module
- Cross-Goal:(同HER)80%选取当前时间步后的某一帧为目标,20%不改变目标
Combining Modular-UVFA and Intrinsically Motivated Goal Exploration
- 整体结构

理论证明
无
实验验证
实验环境:
- Modular Goal Fetch Arm:新建的环境,包含四个Module:Reach, Push, Pick and Place, Stack
baseline:
- HER:将目标集扩展为所有module的目标集的并
- MG-ME:多个专家模型,每个专家模型对应一个module,共享轨迹
实验结果:
- HER无法区分当前初于哪个任务,所以学习难度较大
- MG-ME:多个专家模型同时训练,但不共享参数,所以训练效率较低

可视化学习过程:
- 训练过程中学习不同Module的过程

扰动实验:
- 在某一步增加Push的cube位置扰动,LP能帮助快速恢复

Distracting实验:
- 在4个Module基础上增加干扰任务,增加任务均为不可达任务。LP能帮助智能体快速认识到该任务不可学习。

其他思考
- 在arXiv上发现了有意思的一点,本文在发表前的标题中还出现了"Multi-Task"的关键词,但在发表后不再提及相关概念。其实也可以理解为多任务的一种表现,即一个module对应一个task,但任务具有较强的局限性,module的可替换性和goal在不同module中的可共用性,对任务的限制已经很多了。
- LP值学习进度的估计感觉可以用于多风格化对手的学习中,提供了一种遗忘的评估方式。
