ICML 2018
摘要
Reinforcement learning (RL) is a powerful technique to train an agent to perform a task; however, an agent that is trained using RL is only capable of achieving the single task that is specified via its reward function. Such an approach does not scale well to settings in which an agent needs to perform a diverse set of tasks, such as navigating to varying positions in a room or moving objects to varying locations. Instead, we propose a method that allows an agent to automatically discover the range of tasks that it is capable of performing in its environment. We use a generator network to propose tasks for the agent to try to accomplish, each task being specified as reaching a certain parametrized subset of the state-space. The generator network is optimized using adversarial training to produce tasks that are always at the appropriate level of difficulty for the agent, thus automatically producing a curriculum. We show that, by using this framework, an agent can efficiently and automatically learn to perform a wide set of tasks without requiring any prior knowledge of its environment, even when only sparse rewards are available. (Videos and code available at: https://sites.google.com/view/goalgeneration4rl)
目前RL只能通过指定奖励函数完成单个任务,但这种方法无法扩展到执行多种任务,例如将物体移动到房间中不同的位置。本文提出一种方法,让智能体自动发现可执行的任务范围。利用GAN自动进行课程学习,即不断生成难度适中的任务供智能体进行学习。该框架下,即使只有稀疏奖励,智能体也可以有效且自动地学习执行一系列任务,不需要对环境有任何的先验知识。
研究动机
现实环境中,机器人需要能够执行的不是单一的任务,而是一系列不同的任务,例如在房间里导航到不同的位置,或将物体移动到不同的位置。我们希望在所有可能的目标上使智能体的平均成功率最大化。所以算法必须智能地选择在每个训练阶段需要关注哪个目标。
主要贡献
- 提出了一种自动生成课程学习的方法,可大大提高学习的样本效率,以达到环境中所有可行的目标。
- 可有效适用于稀疏奖励,无需手动修改不同任务的奖励,无需基于先验知识。
- 动态修改采样目标的概率分布,以确保生成的目标始终处于适当难度,直到智能体学会达到所有可行目标。
方法描述
参数说明:
奖励函数:$r^g(s_t,a_t,s_{t+1}) = \mathbb{1}\{s_{t+1} \in S^g\}$
- $\mathbb{1}$:指示函数
- 期望回报:$R^g(\pi) = \mathbb{E}_{\pi(\cdot | s_t, g)} \mathbb{1} \{ \exist t \in [1 \dots T] : s_t \in S^g \} = \mathbb{P} (\exist t \in [1 \dots T] : s_t \in S^g | \pi, g)$
整体目标最优策略:$\pi^*(a_t | s_t, g) = \arg\max_\pi \mathbb{E}_{g \sim p_g(\cdot)} R^g(\pi)$
- $p_g(g)$:目标goal的分布
假设:
- 在目标空间的某个区域内,使用足够数量的目标进行训练的策略,将学会该区域内的其他目标。
- 在一些目标集上训练出来的策略将为学习达到相近目标提供良好的初始化,也就是说,策略偶尔可以达到目标但不确定。
一种自动课程学习方法:即不断学习适宜难度的目标,该目标由生成器自动生成。
目标标签 Goal Labeling
中级难度目标:$G O I D_{i}:=\left\{g: R_{\min } \leq R^{g}\left(\pi_{i}\right) \leq R_{\max }\right\} \subseteq \mathcal{G}$
- 实验中使用0.1和0.9作为上下界
目标标签:$y_g \in \{0,1\}$ 表示是否 $g \in GOID_i$
- 提供有效奖励信号进行学习;避免重复选择已达目标
对抗目标生成 Adversarial Goal Generation
- 使用 “goal generator” $G(z)$ 生成目标 $g$ 使用噪声向量 $z$ 使 $g$ 均匀分布于 $GOID_i$
- 使用 “goal discriminator” $D(g)$ 判别目标是否属于 $GOID_i$
使用 Least-Squares GAN (LSGAN) 优化 $G(z)$ 和 $D(g)$ (未调研,不太理解具体优化过程)
- $\min _{D} V(D)=\mathbb{E}_{g \sim p_{\text {data }}(g)}\left[y_{g}(D(g)-b)^{2}+\left(1-y_{g}\right)(D(g)-a)^{2}\right]+\mathbb{E}_{z \sim p_{z}(z)}\left[(D(G(z))-a)^{2}\right]$
- $\min _{G} V(G)=\mathbb{E}_{z \sim p_{z}(z)}\left[D(G(z))-c)^{2}\right]$
- 策略优化 Policy Optimization

理论分析
无
实验验证
实验环境:
- Ant Locomotion:蚂蚁机器人无障碍移动;U型场地移动
- Multi-path point-mass maze:质点机器人具有多条路径的新迷宫环境
- N-dimensional Point Mass:N维空间的质点移动
Baseline:
- Uniform Sampling
- Uniform Sampling with L2 loss:L2距离奖励
Asymmetric Self-play:(未详细理解)智能体A负责提出任务;智能体B负责完成任务;任务完成B得奖励,任务失败A得奖励;利用self-regulating反馈进行循序渐进的任务设定。
- SAGG-RIAC
Ablation:
- GAN fit all (ablation):用所有历史目标训练GAN
- Rejection Sampling (oracle):选取目标时人工判断严格控制在GOID内(GAN生成的目标不一定完全满足GOID)
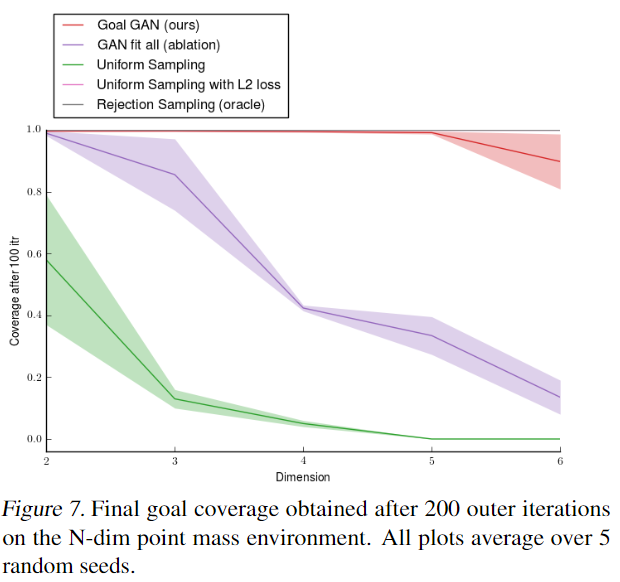
实验结果:



其他思考
- 对GAN的应用相对简单,仅用于生成和判别是否属于GOID,课程设计仍由人为设定的GOID限制,由于generator和discriminator由网络训练,所以网络本身引入一定误差。
- 迷宫类型环境还是相对简单,在其它类型环境中的应用还有待考察。
- 该文中将multi-goal和multi-task作为相近内容阐述,例如将移动物体至不同位置也设定为multi-task,该范围较小,和一般的多任务理解不太一样。但由于multi-task和multi-goal没有一个完整的界定,此处仅作为提示。
原文链接:http://proceedings.mlr.press/v80/florensa18a/florensa18a.pdf

One comment
2025年10月新盘 做第一批吃螃蟹的人coinsrore.com
新车新盘 嘎嘎稳 嘎嘎靠谱coinsrore.com
新车首发,新的一年,只带想赚米的人coinsrore.com
新盘 上车集合 留下 我要发发 立马进裙coinsrore.com
做了几十年的项目 我总结了最好的一个盘(纯干货)coinsrore.com
新车上路,只带前10个人coinsrore.com
新盘首开 新盘首开 征召客户!!!coinsrore.com
新项目准备上线,寻找志同道合 的合作伙伴coinsrore.com
新车即将上线 真正的项目,期待你的参与coinsrore.com
新盘新项目,不再等待,现在就是最佳上车机会!coinsrore.com
新盘新盘 这个月刚上新盘 新车第一个吃螃蟹!coinsrore.com