ICML 2021
摘要
The benefit of multi-task learning over single-task learning relies on the ability to use relations across tasks to improve performance on any single task. While sharing representations is an important mechanism to share information across tasks, its success depends on how well the structure underlying the tasks is captured. In some real-world situations, we have access to metadata, or additional information about a task, that may not provide any new insight in the context of a single task setup alone but inform relations across multiple tasks. While this metadata can be useful for improving multi-task learning performance, effectively incorporating it can be an additional challenge. We posit that an efficient approach to knowledge transfer is through the use of multiple context-dependent, composable representations shared across a family of tasks. In this framework, metadata can help to learn interpretable representations and provide the context to inform which representations to compose and how to compose them. We use the proposed approach to obtain state-of-the-art results in Meta-World, a challenging multi-task benchmark consisting of 50 distinct robotic manipulation tasks.
多任务学习比单任务学习的好处在于能够利用跨任务的关系来提高任何单一任务的性能。虽然共享表征是跨任务共享信息的一个重要机制,但它的成功取决于对任务基础结构的捕捉程度。在一些现实世界的情况下,我们可以获得元数据,或者关于任务的额外信息,这些信息可能不会单独为单个任务的设置提供任何新的洞察力,但会为多个任务之间的关系提供信息。虽然这种元数据对提高多任务学习性能很有用,但有效地将其纳入是一个额外的挑战。我们认为,一个有效的知识转移方法是使用在系列任务中共享的上下文依赖的、可组合的表征。在这个框架中,元数据可以帮助学习可解释的表征,并提供上下文以告知组合哪些表征以及如何组合。我们使用所提出的方法在Meta-World中获得了最先进的结果,这是一个具有挑战性的多任务基准,包括50个不同的机器人操纵任务。
研究动机
现有多任务强化学习(MTRL)的局限性表现为无法利用元数据(描述任务相关的信息)来学习通用技能并在不同任务间进行迁移。元数据可以用来学习一系列编码器,并可以用来为给定任务选择编码器。不同的编码器可以专门用于任务的不同方面,并在任务间进行有效的知识共享。但存在一个开放性问题:选择哪些知识进行迁移,或者决定哪些任务应该一起学习。CARE使用一个混合编码器学习多维表征,由元数据对多维表征进行线性组合。
主要贡献
- 提出一种简单而有效的方法,通过引入任务元数据或上下文信息,以提高采样效率和渐进性能;
- 一种新的MTRL表征学习算法,利用混合可解释编码器,对每个状态空间的任务信息和对象信息进行编码;
- 在Meta-World环境中取得SOTA效果。
方法描述
定义1. CMDP (Contextual Markov Decision Process)
- $<C,S,A,M>$
- $C$:上下文空间
- $S$:状态空间
- $A$:动作空间
- $M$:上下文到MDP参数的映射函数$M(c)=\{R^c,T^c\}$
- $R^c$:奖励函数
- $T^c$:状态转移函数
定义2. BC-MDP (Block Contextual Markov Decision Process)
- $<C,S,A,M'>$
- $M'$:上下文到MDP参数的映射函数$M(c)=\{R^c,T^c, S^c\}$
- $S^c$:局部状态空间,不同任务的状态空间是原始状态的子空间($S^c$的维度是$S$维度的严格子集)
CARE的作用是学习一种能够纳入元数据和功能抽象的表述,其可以与任何策略优化算法结合。
表征设计
- 元数据是高层次的、不明确的和非结构化的,作为对任务的一种描述。该方法仅使用不同任务的描述,例如Meta-World中的"Reach a goal position"、"Push the puck to a goal"。
- 使用预训练模型Roberta将元数据映射到768维的表征,再通过一层MLP将维数降低,即图1中的"Context Encoder"部分,输出$z_{context}$。
算法框架(图1)
- 使用k个编码器将原始状态映射为状态编码$z_{enc}^i$。(k为超参数,一般远小于任务数量)
- 由上下文表征$z_{context}$计算不同编码器对应的软注意力权重$\alpha_i$
所以编码器表征表示为$z_{enc}=\sum_i^k \alpha_i \times z_{enc}^i$
- 文中描述为该表达式直接计算获得$z_{enc}$
- 图1则表示通过注意力加权后还经过一个MLP得到$z_{enc}$
- 最终的状态编码表示为上下文表征和编码器表征的组合,并作为策略优化算法的输入
- 本文使用的策略优化算法为SAC (Soft Actor-Critic)
- 图中的虚线部分表示没有梯度不进行反向传播。

算法流程:

理论分析
无
实验验证
- 实验环境:Meta-World(MT10、MT50),即分别使用机械臂完成10和50个任务。
- Baselines:Multi-task SAC(不进行任务区分);Multi-task SAC + Task Encoder(外加任务编码);Multi-head SAC(共享网络后针对不同任务有独立网络);PCGrad(梯度手术方法);Soft Modularization(在共享策略网络中执行路由以学习不同任务的不同策略);SAC + FiLM(一种通用调节方法);One SAC agent per task(所有任务独立训练,上界)
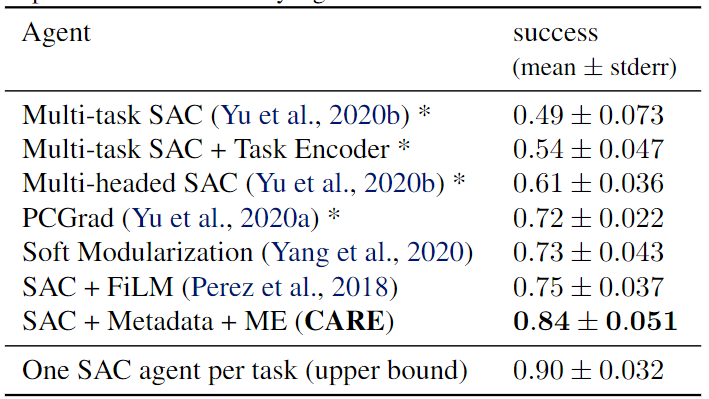
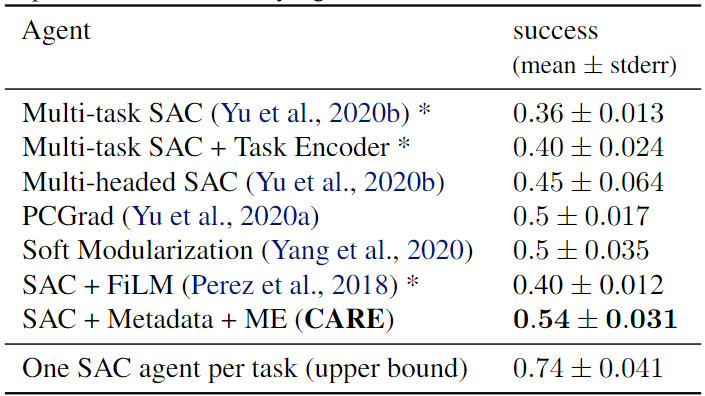
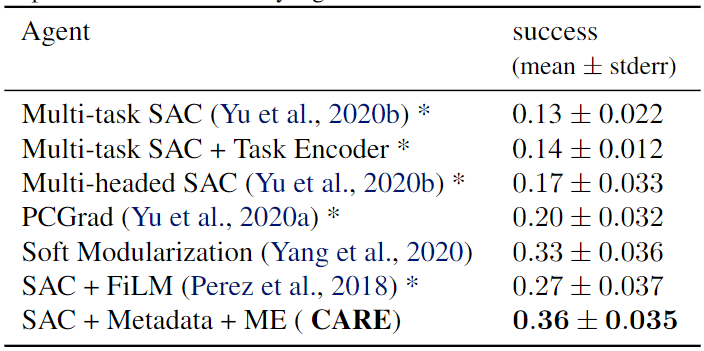
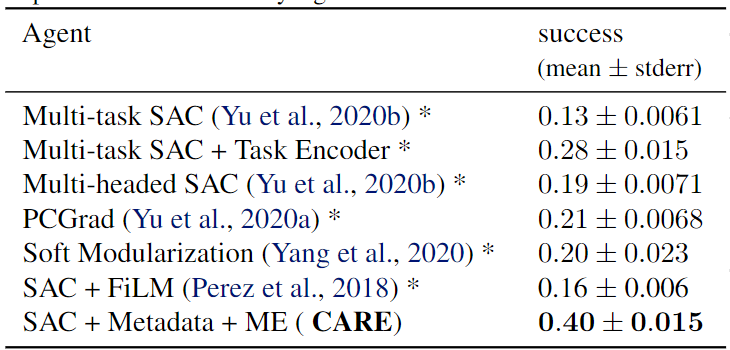
Ablation:
- SAC + ME(不使用元数据);SAC + Metadata(不使用混合编码器)
- 实验结果表明Metadata对算法提升更大
- 实验设置:MT10 + 2e6 steps

Visual Investigation:
- 对比任务之间的相似度,相似度定义为计算两个向量的余弦值
- (a) 为MT10中10个任务的自然语言描述(即元数据)
- (b) 为预处理模型输出向量的相似度
- (c) 为6个编码器组成的CARE输出表征编码$z_{enc}$相似度
- (d) 为不使用元数据的表征编码相似度
- 结果说明元数据的引入使得编码能够更好的表征任务间的关系

Zero-shot generalization:
- 将策略泛化到从未训练过的任务当中,在MT10除“drawer-open-v1”和“window-open-v1”的环境中进行训练,并直接在这两个环境中进行测试。
- 原文也指出PCGrad与SM本身并不具有获取未知任务信息的能力,这种对比并不公平,只是为了强调元数据对于zero-shot泛化的好处。不过对于同样使用元数据的FiLM,CARE表现更佳。

其他思考
- 该方法的主要贡献在于引入元数据提升MTRL的性能,元数据任务编码相比one-hot直接编码可以提供更多的有效信息,用于获取不同任务间目标、技能的相似性,这里应用了NLP领域的相关知识。
- 该方法中基于注意力的混合编码器已经是一种普遍的网络架构,有点类似于谷歌之前提出的用于MTL的MMOE模型,个人觉得文中对于多编码器的解释比较牵强,文章认为每个编码器都编码了部分状态信息,若相似任务应该利用了相似的部分状态信息,则对应的注意力权重可能类似。但文章并没有给出对应的可视化分析,例如任务对象都是“门”的任务是否在某一编码器的输出中表现出强相似性,对象是“门”或“窗”的任务表现出强相似性的编码器是否是同一个,若是则可以简单理解为该编码器主要针对任务对象。
